

Recently, the study “A Multicenter Multifunctional Assessment of Large Language Models in Pure-Tone Audiogram Interpretation for Patients,” conducted by the team of Professor Lei Jianbo, joint professor at the Peking University Institute for Global Health and Development and the Peking University Medical Informatics Center, was officially published in NPJ Digital Medicine, a Nature Portfolio journal. (IF: 15.1; JCR: 1/185 in Health Care Sciences & Services, 2/48 in Medical Informatics). This study is the first to systematically assess the performance of eight mainstream large language models in pure-tone audiogram diagnosis, patient-oriented interpretation, and personalized recommendation tasks, providing an important benchmark for the auxiliary application of AI in hearing health.
Research Background
Hearing loss is the third leading cause of disability worldwide. The World Health Organization estimates that by 2050, nearly 2.5 billion people globally will be affected by hearing loss. Pure-tone audiograms are the “gold standard” for evaluating hearing loss, but their graphical format is highly technical and their conclusions are often highly summarized, making them difficult for ordinary patients to understand independently. At the same time, hearing care resources are unevenly distributed around the world, and physicians face heavy workloads, making it difficult to provide detailed individualized interpretation and guidance. Large language models have powerful natural language understanding and generation capabilities, but whether they can “understand” medical chart-based reports had not previously been empirically studied.
Research Methods: Multicenter, Blinded, and Multidimensional Assessment
The research team collected 140 real-world pure-tone audiogram reports from the Second Affiliated Hospital of Zhejiang University School of Medicine and the Hangzhou Hearing Center, covering different severities and types of hearing loss. Eight large language models from four leading institutions in China and the United States were selected, including DeepSeek-V3, DeepSeek-R1, ChatGPT-4o, ChatGPT-o3, Gemini 2.0 Flash, Gemini 2.0 Flash Thinking, Kimi-V1, and Kimi-K1.5.
Each model was required to complete three consecutive tasks: first, diagnosing the degree and type of hearing loss; second, interpreting the report in patient-friendly language; and third, providing personalized health recommendations. The assessment combined objective indicators, including diagnostic accuracy, readability, and hallucination rate, with subjective indicators, including expert ratings and public ratings. All evaluations were conducted under blinded conditions.
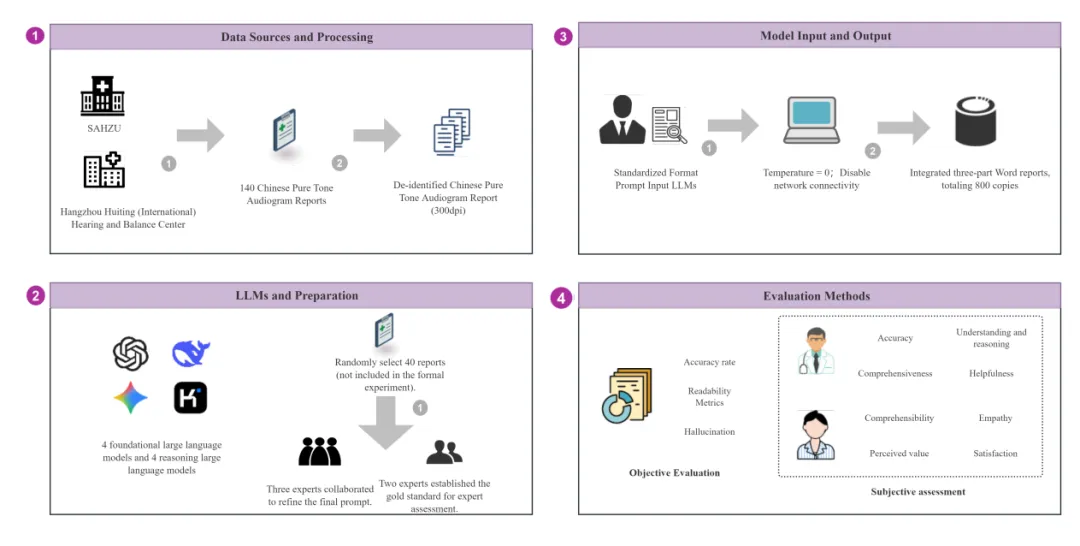
Main Findings
The study showed that DeepSeek-V3 achieved the highest diagnostic accuracy, with 67.0% accuracy for the degree of hearing loss and 54.0% accuracy for the type of hearing loss, significantly outperforming the other models (p<0.01). Gemini 2.0 Flash Thinking had the lowest hallucination rate, at 4.00%. DeepSeek-R1 was the most suitable for public reading, with a FKGL score of 6.41 (95% CI, 5.93–6.98), while Kimi-K1.5 was overly professional in style, with a FKGL score of 10.17 (95% CI, 8.90–11.40). Members of the public perceived Gemini 2.0 Flash/Thinking as more beneficial in helping them understand the reports and meeting their emotional needs. Although DeepSeek-R1 led in professional evaluation, it received the lowest scores in user satisfaction (3.44; 95% CI, 3.34–3.54) and empathy (3.33; 95% CI, 3.19–3.46). All models faced challenges in understanding pathological mechanisms and controlling hallucinations.
Research Significance
This study is the first to assess LLMs’ ability to understand professional medical image-based reports, with a specific focus on their potential in interpreting pure-tone audiogram reports. The evaluation covered diagnostic accuracy, comprehensiveness of report interpretation, and effectiveness of user communication. In terms of audiogram-based diagnosis, even DeepSeek-V3, the model with the highest diagnostic accuracy, remained far below physician-level performance, and hallucinations occurred frequently. This indicates that these models are not yet capable of fully replacing professional physicians.
However, in report interpretation and professional recommendation tasks, LLMs demonstrated the potential to generate content that is highly helpful to patients. This study fills a gap in the evaluation of LLM applications in audiology, reveals the important influence of task characteristics and input formats on LLM performance in medical settings, and identifies current limitations in chart processing, professional accuracy, and the balance between technical rigor and user-friendliness. Future technical optimization should target these limitations. Through continued improvements in domain-adapted training and hallucination risk control, LLMs may become an important tool for addressing global inequalities in hearing healthcare resources, especially in areas with limited medical resources.
Original article link: https://www.nature.com/articles/s41746-026-02537-1

